Ha! Yeah that’s me. Thanks! Vitalik actually wrote some Viper code to do a batch auction after that post. Was surprised (and not too delighted) when Uniswap then went the other way.
6 Likes
This proposal is an improvement on the previous Proof of Work relay scheme, but I think still misses some of the objectives.
As I see it, an MEV mitigation scheme has 3 main objectives:
- Move some of the money that searchers are earning, or currently wasting on latency reduction, to the Arbitrum ecosystem.
- Eliminate the need for latency races by the searchers, to remove the need for spamming transactions or creating 1000s of connections to the sequencer feed
- Achieve the above while damaging the regular customer experience as little as possible
I think this proposal will do a reasonable job of objective 1, although there could be other strategies that will lead to a higher proportion of MEV being paid to the ecosystem
I don’t think this proposal will eliminate the searcher speed races. In the limit of large fees, the time savings a searcher is purchasing (compared to no added latency) will be proportional to gc/F. So when trying to save the last fractions of a millisecond, that will prove very expensive, and hence still worth searchers making many sequencer connections.
On objective 3, one of the main selling points of the Arbitrum ecosystem is its low transaction latency. Even for the regular customer, most transactions will return a response in < 300ms. So to suddenly add an extra 500ms to everyone’s transactions seems like destroying the elegant and efficient system you currently have. Plus messing with the simplicity of FCFS will likely introduce a whole load of new exploits for searchers (blind spamming for sandwich attacks perhaps).
If you want to charge searchers for preferential access, I suggest imposing the delay on the outbound sequencer feed side. That seems much less manipulatable, more controllable, and less impactful on the regular user. For instance, a daily lottery or auction for non-delayed sequencer feed connections. This would be similar to the previous proof of work suggestion, but without the PoW. I’d be happy to work with the team designing a lottery smart contract for ordering of sequencer connections.
4 Likes
Regarding the time delay, it also seems that FBA-FCFS could actually have a better UX on average than Time Boost for a given batch time = delay default based on my understanding here?
-
Time Boost - All user txs delayed by 500ms speed bump by default upon receipt.
-
FBA-FCFS - Batch time is 500ms, so user txs received during the window can be included within it, on average <500ms closer to the midpoint.
There would be more variability in the latter (could slip to next batch depending on receipt time), but inclusion time for txs not paying priority fees should on average be lower (<500ms upon receipt).
4 Likes
Any block-to-block approach (e.g. proposed batch auction) would create situations where one transaction arrives at the end of the block with low bid, and another, much higher bid transaction arrives right after this block. Then, low bid transaction is always scheduled in front of the high bid transaction. We describe when such situation might arrise and why low latency is more important in block-to-block approach than in time boost setting. For simplicity, assume there are only two parties. Generalization to more parties is trivial. Suppose the first party (denoted by A) can reach sequencer in 0.05 seconds, and the second party (denoted by B) can reach in 0.1 seconds. Then, A can wait until 0.5-0.05=0.45 seconds pass since the beginning of a new block creation, and send its transaction to at exactly 0.45, while B has to send its transaction to be included in this block until 0.4 seconds pass. That is, in (0.1-0.05)/0.5 = 10% of the cases (in time interval 0.4-0.45) B has no chance to win a single race over A, even if it values arbitrage much more than A (and would be willing to bid much higher than A). In Ethereum environment this is not a big problem, as A would only have advantage in 0.05/12 or approximately 0.4% of the cases (see Latency arms race concerns in blockspace markets - Economics - Ethereum Research (ethresear.ch) for a related discussion). That is, latency is 12/0.5 = 24 times more important in this case. It is easy to see that our proposal of time boost fee does not suffer from this.
There is another clear advantage of waiting until the last feasible point in the block-to-block approach, as a party with latency advantage simulates more strategies and finds better arbitrages. It is interesting how to quantify such advantage.
4 Likes
Yes aware, I mentioned this in several comments above. That last look advantage is a well understood property of this kind of discrete time auction, can see the Budish paper as well. The reality though is that delta is nowhere near the 20x you mention here. The relevant difference here for capturing an opportunity is the difference between:
- “fast searcher” vs. “slow searcher” (negligible difference)
Not relevant:
- “fast searcher” vs. “regular user” (large difference, as you note)
Regular user txs aren’t competing in a race for a specific arb or anything against searchers. They just want to keep their txs private and be included relatively quickly.
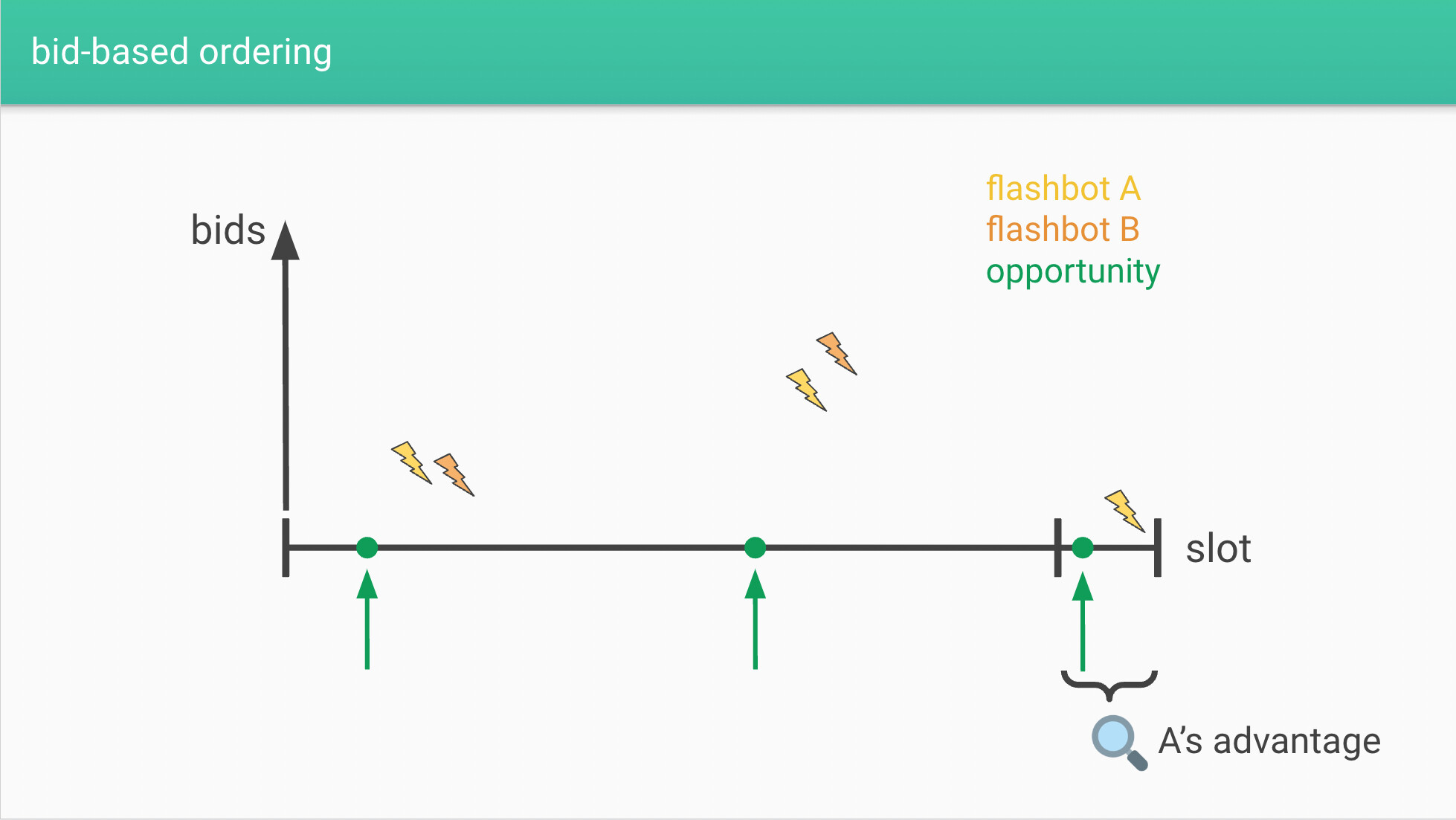
This marginal benefit left seems smaller than the benefit of latency in the Time Boost scenario, where the latency advantage is always present (you can always bid less). This is particularly relevant in the case of high value opportunities where the Time Boost is worth a lot as you go further down the curve.
1 Like
(I’m being limited as a new account in number of comments/media allowed so posting separately)
Overall this is clearly an improvement vs. today, but just seems less favorable on the tradeoff spectrum vs. fast batching and harder to decentralize as mentioned above as well.

2 Likes
Thank you for your engagement. I changed your previous account’s trust level, so you should be able to post more now.
Regarding expressiveness: we can not allow reverting at this level. That would require adding validators and block proposals, basically copying Ethereum infrastructure. We want to keep transaction ordering on a protocol level. Therefore, FBA-FCFS (or any other mechanism) you’re proposing would also be all-pay-auction. Regardless of this (implementation) point, I think all-pay-auctions on average do not cause extra waste, compared to only winner pays auction, but we need to check it formally. I wrote about it informally above.
Regarding second row: we chose 500ms for this reason, for it to be low enough, not to make UX much worse, which I think it gives yellow status. If we could increase delay g even further, then 1st row for Time Boost would become greener. So there is a tradeoff here. We have actually studied this tradeoff formally, in the equilibrium, concluding that increasing g (to infinity) decreases investment in latency advantage (to zero), and for a fixed latency cost function, we can exactly pin down the speed of convergence of latency investment.
3 Likes
This is just revenue equivalence. If you assume risk neutrality (at least approximately), then bidders just shade their bid more in the all pay auction, and on average they have the same likelikood of winning and they have the same expected payment. This is of course when we analyze decision at the point of bidding. Ex-post people might dislike an outcome where they pay if they don’t win.
1 Like
One thing to note here is that this is a priority fee, and is collected exactly as the Ethereum priority fee, which means it is a fee per-gas, and charged on each transaction. So the “bid” is for a transaction, not for a block nor a bundle of transactions.
Of course, a submitter can always bundle multiple logically separate transactions together, but there isn’t much advantage to doing this because the fee is charged per gas, so bundling only saves a little by amortizing the 21,000 intrinsic per-transaction gas that Ethereum (and Arbitrum) charges.
If there are multiple “races” happening simultaneously, with some profit opportunity for the first included transaction in each race, it makes sense for a submitter to bid separately in each race, and the time boost mechanism has the nice property that the bidding in one race doesn’t affect who wins some other race. (That would not be the case for a single winner-take-all auction.)
4 Likes
From what I can tell, this is the only rationale given for why this new ordering policy should be adopted. To break down the argument, the underlying problem is that Arbitrum has a centralized sequencer run by Offchain Labs. Recently, Offchain Labs reportedly ran into issues with the sequencer because searchers were establishing too many connections to the sequencer, posing a DoS threat (Add a relay client connection nonce by PlasmaPower · Pull Request #1504 · OffchainLabs/nitro · GitHub). So the problem that this proposal is supposedly trying to solve is to prevent the centralized sequencer from Offchain Labs being DoSed.
This is a symptom of the larger problem, namely that the sequencer is centralized. If you run a centralized system, of course you run the risk of a complete failure because it literally has a single point of failure. Even if time boost were adopted, the sequencer could still get attacked by any regular DDoS attack, it could go down due to misconfiguration, network outage in the datacenter, Offchain Labs can censor transactions (temporarily), reorder transactions to their liking, perform MEV and censor other searchers, …
To me, the obvious way to go is to decentralize the sequencer. With a sufficiently sized network, there would no longer be a single point of failure. There would not be a single point that all searchers are rallying to, and they would not be able to harm the sequencer. And of course, the sequencer should be decentralized regardless, to remove trust from Offchain Labs and really make Arbitrum decentralized.
I also have not seen any mention of where the priority fee would go. Would Offchain Labs pocket the fees? This would obviously be a huge opportunity for them, but in that case they should be fully transparent about it. Searchers will always spend money to try and gain more profits, whether it is invested in optimizing latency or on priority fees. The arms race between searchers can not be stopped. But why does Offchain Labs even care about this arms race? I honestly don’t know, but priority fees would be an easy way for the money spent by searchers to flow directly to Offchain Labs.
It is also to be questioned whether the priority fee would really eliminate the latency race. At some point, gaining an extra X time will cost more if gained via priority fee than by spending that money into optimizing latency.
I don’t want to sound too harsh, but it surprises me that a lot of my arguments have not been voiced by others before. To me, this proposal completely misses the point, or Offchain Labs is not being honest about what the point of this proposal is. If implemented, the sequencer would still be as vulnerable as before, searchers would still invest a lot of resources on being able to make profits, including optimizing latency, but Offchain Labs could suddenly start pocketing a large portion of the resources spent by searchers. This seems like a step backwards in terms of decentralizing Arbitrum.
2 Likes
Sequencer decentralization is an important topic for the community to discuss. But I think it’s a separate issue from what the transaction ordering policy should be, which is the topic of this thread.
(For now, the centralized sequencer is deployed with redundancy and a fail-over capability, so something like the failure of a data center shouldn’t stop the sequencer.)
The Arbitrum One and Nova chains are governed by the Arbitrum DAO, and the DAO will decide where any fee revenue generated by those chains will go. So if the DAO decides to adopt some policy on its chains that generates revenue from those chains, the DAO can decide where that revenue goes.
3 Likes
It seems though that Arbitrum was happy with its FCFS ordering policy until the lack of rate limiting on the sequencer triggered this nightmare proposal. The timing of the time boost proposal is interestingly correlated with the backlash that the PoW proposal received. I think it is a similarly bad proposal.
Implementing time boost turns MEV from an engineering problem into a money problem. Have the money to pay for time boost? Welcome to the club. The rich get richer, the poor get poorer:
With FCFS, MEV is mostly an engineering problem which has an inherent fairness to it. Have the time and skills to make the fastest algorithm and you can make profits. No matter how many ETH you own. Time boost, on the other hand, puts up a huge barrier to entry. While still requiring the same amount of engineering and time to develop any kind of MEV application, it additionally requires a lot of money to be spent on time boost, especially for initial experimentation, testing, debugging, etc, before ever even making any profitable MEV trades. Those that can take the risk of losing money, i.e. the rich, will take it and make the investment. Those that don’t, i.e. everyone else, won’t and will be cut out of the picture.
3 Likes
A paper analyzing economic aspects of time boost: https://arxiv.org/pdf/2306.02179.pdf. Some of the earlier concerns (e.g., given by @bbuddha) in this thread are also addressed. In short, time boost does not remove all investment from the latency competition, but rather moves most of it to bidding, when initialized with correct parameters. We also discuss some implementation details of the decentralized sequencer committee.
4 Likes
(Cross-post from the Flashbots forum)
I have written a longer analysis about the relative performance of time boost and a batch auction design: Batching, Bidding and Latency Feedback and comments are very welcome.
A specific proposal for implementing Timeboost on Arbitrum chains is here.